Samenvatting
Die Evolution der Datenengineering macht serverlose Compute-Notebooks, Lakeflow-Jobs und deklarative Pipelines von Spark effizienter und zugänglicher.
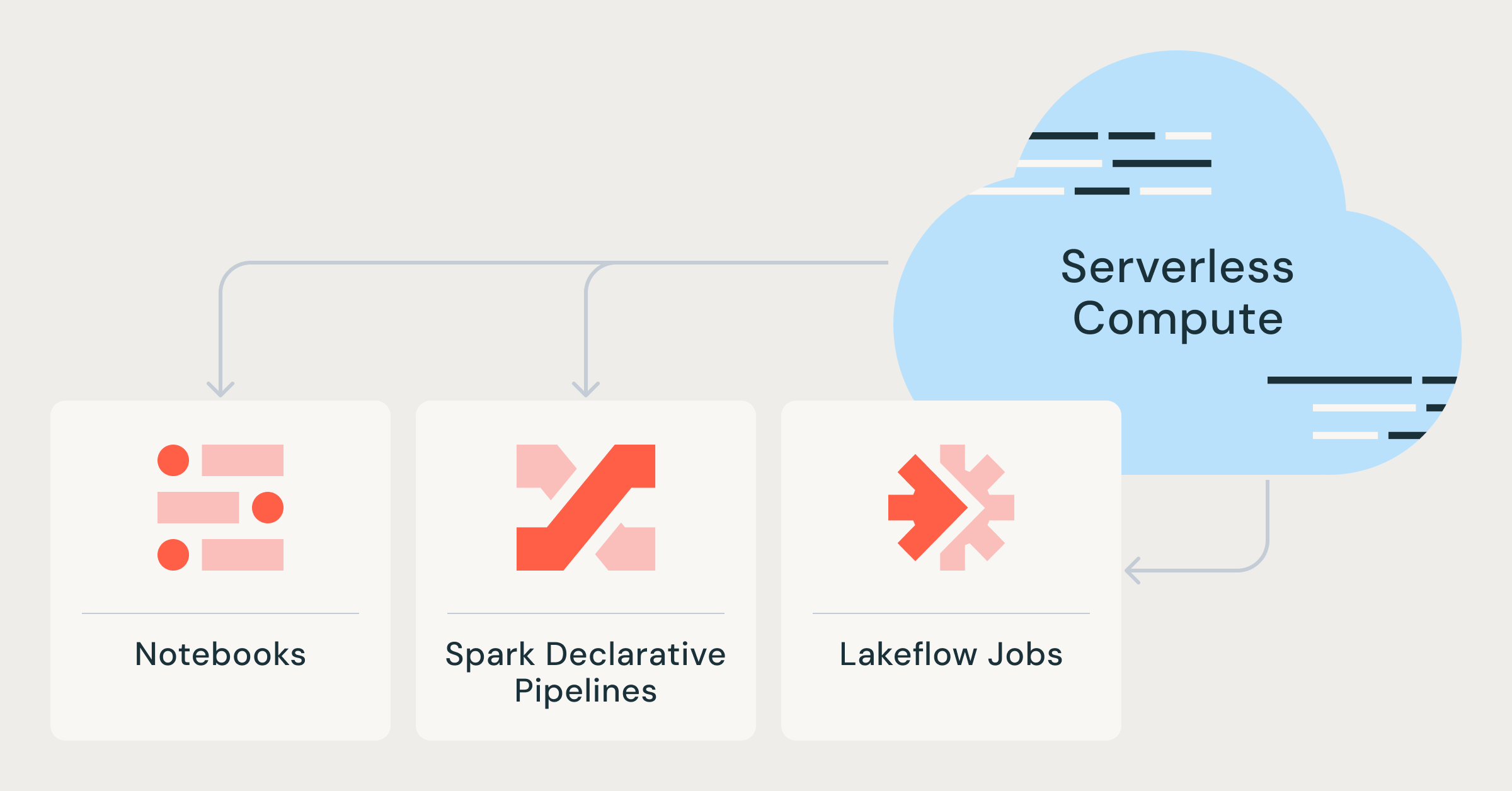
Innovationen im Datenengineering
Das Datenengineering durchläuft derzeit einen tiefgreifenden Wandel durch die Integration von serverlosen Technologien. Databricks bringt Verbesserungen mit serverlosen Compute-Notebooks und Lakeflow-Jobs auf den Markt, die es Organisationen ermöglichen, agiler auf ihre Datenanalysebedürfnisse zu reagieren. Zudem werden deklarative Pipelines in Spark durch diese Innovationen einfacher zu implementieren und zu verwalten.
Auswirkungen auf den BI-Markt
Für BI-Profis bedeutet diese Entwicklung den Zugang zu Tools, die die Zeit von der Datenerfassung bis zur Einsicht erheblich verkürzen. Wettbewerber wie Snowflake und Google BigQuery bieten ebenfalls serverlose Möglichkeiten an, was den Wettbewerb auf dem Markt verstärkt. Der Trend zu serverlosen Architekturen deutet auf eine breitere Verschiebung hin, die sich flexibleren, skalierbaren Lösungen zuwendet und traditionelle Datenplattformen unter Druck setzt.
Wichtige Erkenntnis für BI-Profis
BI-Profis müssen sich an diese schnelleren und effizienteren Toolsets anpassen, um wettbewerbsfähig zu bleiben. Es ist entscheidend, sich mit serverlosen Technologien vertraut zu machen und die Möglichkeiten zu erkunden, die diese neuen Plattformen bieten, um die Datenanalyse zu optimieren.
Deepen your knowledge
Knowledge Base
AI in Power BI — Copilot, Smart Narratives and more
Discover all AI features in Power BI: from Copilot and Smart Narratives to anomaly detection and Q&A. Complete overview ...
Knowledge BaseChatGPT and BI — How AI is transforming data analysis
Discover how ChatGPT and generative AI are changing business intelligence. From generating SQL and DAX to automating dat...
Knowledge BasePredictive Analytics — What can it do for your business?
Discover what predictive analytics is, how it works, and how to apply it in your business. From the 4 levels of analytic...