Summary
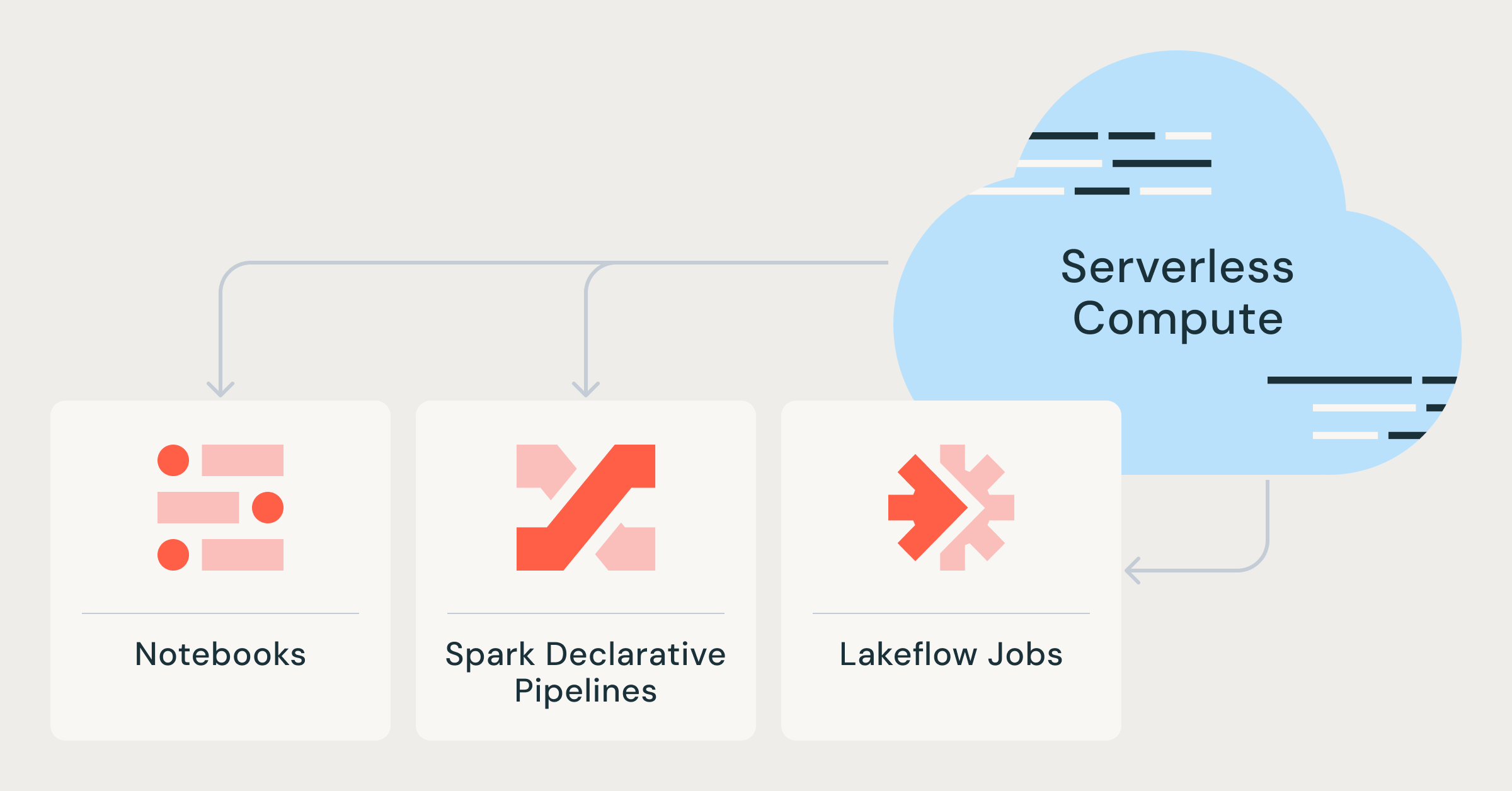
The evolution of data engineering makes serverless compute notebooks, Lakeflow jobs, and Spark declarative pipelines more efficient and accessible.
Innovations in data engineering
Data engineering is currently undergoing a significant transformation due to the integration of serverless technologies. Databricks is rolling out enhancements with serverless compute notebooks and Lakeflow jobs, enabling organizations to be more agile and responsive to their data analysis needs. Additionally, declarative pipelines in Spark are becoming easier to implement and manage thanks to these innovations.
Impact on the BI market
For BI professionals, this evolution means access to tools that dramatically reduce the time from data acquisition to insight. Competitors such as Snowflake and Google BigQuery are also offering serverless capabilities, increasing the competition in the market. The trend towards serverless architectures signals a larger shift towards flexible, scalability-focused solutions, putting traditional data platforms under pressure.
Key takeaway for BI professionals
BI professionals must adapt to these faster and more efficient toolsets to remain competitive. It is crucial to familiarize themselves with serverless technologies and explore the opportunities these new platforms offer to optimize data analysis.
Deepen your knowledge
Knowledge Base
AI in Power BI — Copilot, Smart Narratives and more
Discover all AI features in Power BI: from Copilot and Smart Narratives to anomaly detection and Q&A. Complete overview ...
Knowledge BaseChatGPT and BI — How AI is transforming data analysis
Discover how ChatGPT and generative AI are changing business intelligence. From generating SQL and DAX to automating dat...
Knowledge BasePredictive Analytics — What can it do for your business?
Discover what predictive analytics is, how it works, and how to apply it in your business. From the 4 levels of analytic...